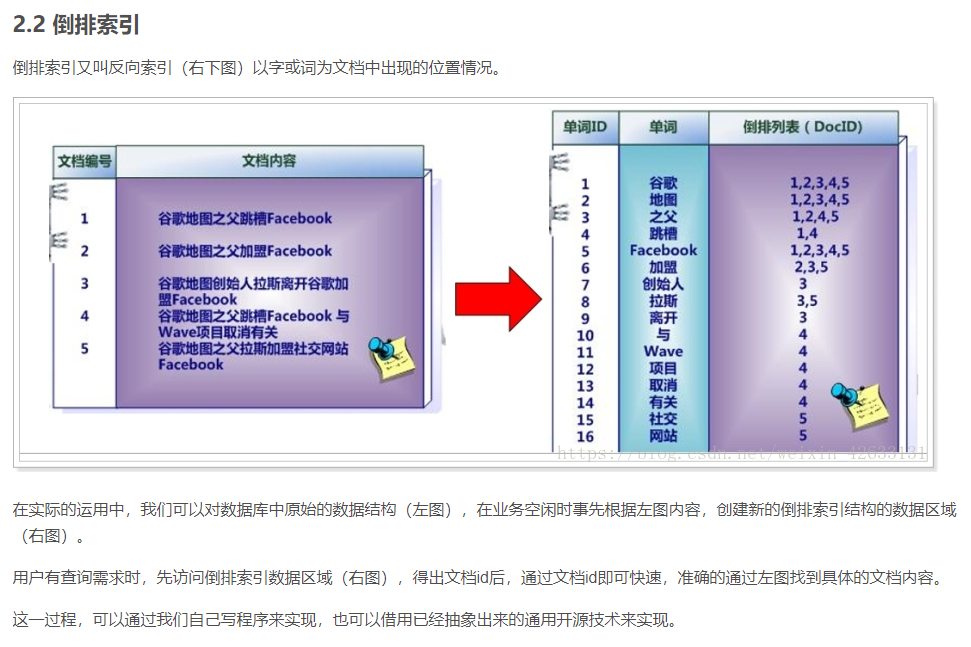
ASM Automated Storage Management 自动存储管理
ASM 是 Oracle 数据库 10g 中一个非常出色的新特性,它以平台无关的方式提供了文件系统、逻辑卷管理器以及软件 RAID(磁盘阵列) 等服务。ASM 可以条带化和镜像磁盘,从而实现了在数据库被加载的情况下添加或移除磁盘以及自动平衡 I/O 以删除“热点”。它还支持直接和异步的 I/O 并使用 Oracle9i 中引入的 Oracle 数据管理器 API(简化的 I/O 系统调用接口)。
RAC 缩写 real application cluses 实时应用集群
RAC是real application clusters的缩写,译为“实时应用集群”, 是Oracle新版数据库中采用的一项新技术,是高可用性的一种,也是Oracle数据库支持网格计算环境的核心技术。
CRS Oracle Cluster Ready Service(Oracle集群就绪服务),简称CRS
在10g和11.1,Oracle的集群称为CRS(Oracle Cluster Ready Service), 在11.2,Oracle的集群称为GI (Grid Infrastructure)。 对于CRS/GI,他们的一些核心进程的功能基本类似,但是在11.2,新增了很多新的Deamon进程。
从Oracle 10gR1 RAC 开始,Oracle推出了自身的集群软件,这个软件的名称叫做Oracle Cluster Ready Service(Oracle集群就绪服务),简称CRS。从Oracle 10gR2开始,包括最新的11g,Oracle将其更名为Clusterware(集群件),但通常意义上我们认为CRS = Clusterware = Oracle Cluster Ready Service = Oracle Cluster Software.
CRS一般用来搭建Oracle的并行数据库,即RAC,但除了与RAC的接口之外,CRS还提供了一组高可用性的应用程序接口(API),用来搭建一般应用程序的高可用集群,即一般我们常说的双机热备,比如使用CRS实现MySQL的双机热备。
OCR Oracle cluster register Oracle Configuration Repository
CVU Cluster Verification Utility
在安装RAC的过程中,如果没有安装cvuqdisk包,那么集群检验工具(Cluster Verification Utility,CVU)就不能发现共享磁盘。而且,如果没有安装该包或者安装的版本不对的话,那么当运行集群检验工具的时候就会报“PRVF-10037 : Failed to retrieve storage type for “” on node “””或“Could not get the type of storage”或“PRVF-07017: Package cvuqdisk not installed”的错误。cvuqdisk的RPM包含在Oracle Grid Infrastructure安装介质上的rpm目录中。以root用户在RAC的2个节点上都进行安装
ACD = Active Change Directory
ACFS = ASM Cluster File System
ADDM = Automatic Database Diagnostic Monitor
ADR = Automatic Diagnostic Repository
ADVM = ASM Dynamic Volume Manager
AIO = Asynchronous I/O
AMDU = ASM Metadata Dump Utility
AMM = Automatic Memory Management
ARC = Archive process
ASH = Active Session History
ASM = Automatic Storage Management
ASMB = ASM Background process
ASMCA = ASM Configuration Assistant
ASMCMD = ASM CoMmanD line utility
ASMLIB = ASM LIBrary tool
ASMM = Automatic Shared Memory Management
ASMSNMP = ASM Simple Network Management Protocol
AT = Allocation Table
ATA = Advanced Technology Attachment
AU = Allocation Unit
AWR = Automatic Workload Repository
BH = Block Header
BMC = Baseboard Management Controller
BS = Block Size
CBO = Cost-Based Optimizer
CF = Control File
CFS = Cluster FileSystem
CHM = Cluster Health Monitor
CIO = Concurrent I/O
CKPT = ChecKPoinT process
CLUVFY = CLUster VeriFy utility
COD = Continuing Operation Directory
CPU = Central Processing Unit or Critical Patch Update
CRM = Customer Relationship Management
CRS = Cluster Ready Services
CSS = Cluster Synchronization Services
CSV = Comma-Separated Values
CVM = Cluster Volume Manager
DB = DataBase
DBCA = DataBase Configuration Assistant
DBFS = DataBase File System
DBM = DataBase Machine
DBMS = DataBase Management Systems
DBPERF = DataBase PERFormance
DBV = DataBase Verification tool
DBW = DataBase Writer process
DD = Disk Directory or Data Description tool
DES = Database Excelleration Systems Inc.
DG = DiskGroup
DH = Disk Header
DIO = Direct I/O
DISM = Dynamic Intimate Shared Memory
DM = Device Mapper
DNFS = Direct Network File System
DRAM = Dynamic Random Access Memory
DSS = Decision Support System
DUL = Data UnLoader
DW = Data Warehouse
EIDE = Enhanced Integrated Drive Electronics
ERP = Enterprise Resource Planning
ETA = Estimated Time of Arrival
ETL = Extract Transform Load
FD = File Directory
FG = FailGroup
FRA = Flash Recovery Area or Fast Recovery Area
FS = FileSystem
FST = Free Segments Table
FTS = Full Table Scan
GC = Grid Control
GI = Grid Infrastructure
GUI = Graphical User Interface
HA = High Availability
HARD = Hardware Assisted Resilient Data
HB = Heart Beat
HBA = Host Bus Adapter
IDE = Integrated Drive Electronics
IIS = Internet Information Services
INST = INSTance
IO = Input/Output
IOPS = IO Per Second
IOT = Index Organized Table
IP = Internet Protocol
IPMI = Intelligent Platform Management Interface
JET = Joint Escalation Team
JFS = Journaled FileSystem
KB = KiloByte
KFED = Kernel Files metadata EDitor
KFOD = Kernel Files Osm disk[group] Discovery
LGWR = redo LoG WRiter process
LLT = Veritas Low Latency Transport protocol
LSNR = LiSteNeR
LUN = Logical Unit Number
LVM = Logical Volume Manager
MAA = Maximum Availability Architecture
MB = MegaByte
NAS = Network Attached Storage
NetApp = Network Appliance
NETCA = NETwork Configuration Assistant
NFS = Network FileSystem
NIC = Network Interface Controller
OCFS = Oracle Cluster FileSystem
OCR = Oracle Cluster Registry
ODM = Oracle Disk Manager
ODS = Operational Data Store
OEL = Oracle Enterprise Linux
OEM = Oracle Enterprise Manager
OID = Oracle Internet Directory
OLAP = OnLine Analytical Processing
OLTP = OnLine Transaction Processing
OMS = Oracle Management Service
OPATCH = Oracle PATCHing utility
OS = Operating System
OSCP = Oracle Storage Compatibility Program
OSW = OS Watcher
OSWFW = OS Watcher For Windows
OTN = Oracle Technology Network
OUI = Oracle Universal Installer
PB = PetaByte
PFILE = Parameter FILE
PGA = Program Global Area
PID = Proces ID
PL/SQL = Procedural Language/Structured Query Language
POC = Proof Of Concept
PROCWATCHER = PROCess WATCHER
PST = Partnership Status Table
PSU = Patch Set Update
PX = Parrallel eXecution
RAC = Real Application Cluster
RAID = Redundant Array of Independent Disks
RAM = Random Access Memory
RBAL = ReBALance process
RCA = Root Cause Analysis
RDA = Remote Diagnostic Agent
RDBMS = Relational DataBase Management System
RHEL = RedHat Enterprise Linux
RM = Resource Manager
RMAN = Recovery MANager
RPM = Resource Package Manager
SAN = Storage Area Network
SAS = Serial Attached SCSI
SATA = Serial Advanced Technology Attachment
SCAN = Single Client Access Name
SCSI = Small Computer System Interface
SGA = System Global Area
SLA = Service Level Agreement
SMF = Service Management Facility
SPFILE = Server Parameter FILE
SQL = Structured Query Language
SRDF = EMC Symmetrix Remote Data Facility
SSD = Solid State Disk
SVCTM = average SerViCe TiMe
SVM = Solaris Volume Manager
TB = TeraByte
TCP = Transmission Control Protocol
TDE = Transparent Data Encryption
TKPROF = Transient Kernel PROFile
TNS = Transparent Network Substrate
UDEV = Unix DEVice manager
UDP = User Datagram Protocol
UFG = Umbilicus ForeGround process
UFS = User FileSystem
VBG = Volume BackGround process
VCS = Veritas Cluster Server
VD = Voting Disk
VDBG = Volume Driver BackGround process
VIP = Virtual Internet Portocol
VLDB = Very Large DataBase
VM = Virtual Machine
VMB = Volume Membership BackGround process
VxFS = Veritas File System
VxVM = Veritas Volume Manager
XDB = XML DataBase